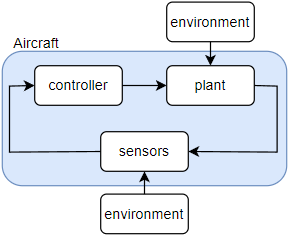
Embedded software is integral to modern technology, ranging from simple home appliances to advanced autonomous systems. It can be broadly classified into two categories: simple (Non-OS) and complex (OS-driven) embedded software.

Simple Embedded Software: When simplicity and low cost are priorities and an OS would be overkill
Examples:
- Power or temperature monitoring systems.
- Simple applications in household appliances like ovens and washing machines.
Characteristics:
- Typically designed for applications with few tasks.
- No operating system necessary.
- Software interacts directly with the microcontroller’s hardware (registers etc.), forcing rewrites if the hardware changes.
Advantages:
- Low power consumption, low cost.
- Can be developed by electronics engineers, no need for computer engineers because basic embedded programming knowledge is sufficient.
- Deterministic: By sidestepping the complexity of OS schedulers, simple systems achieve predictable performance.
- Fewer abstraction layers make verification and validation straightforward, which is a huge advantage for safety-critical certification.
Complex Embedded Software: When multi-tasking, file operations and networking necessitate an OS
Examples:
- IoT devices requiring seamless connectivity.
- Systems involving advanced sensor integration or navigation.
Characteristics:
- Runs on an operating system that manages tasks and system resources.
- Capable of handling multiple tasks and applications simultaneously.
- Safety-critical certification is difficult. To make it easier, safety-critical parts should be developed as separate, simpler modules.
Advantages:
- Less competition and higher profit margins, provided that you have a strong technical team.
- Requires computer engineers to lead the development because of increased software complexity. Besides embedded software courses, related concepts of algorithms, data structures, and operating systems are also a core parts of computer engineering but not electronics engineering.
- The OS abstracts low-level hardware management, enabling developers to focus on application logic. A POSIX-compliant application, for instance, can run on any POSIX-supporting OS with minimal changes.
- Easier for new developers to adapt and contribute due to less hardware dependency.
- A broad range of pre-existing libraries simplifies development.
- Operating systems provide abstraction layers (e.g., Linux Device Model), allowing drivers to expose standard interfaces while interacting with specific hardware.
- Simplifies adding new functionality (e.g. telemetry) or adapting to new hardware (e.g. new/different sensors).
- With minor modifications, software can be tested on a PC, speeding up testing with less effort (no need for electronic cards, power supplies, etc.) and reducing bugs.
Music: Peyk - Don Kafa